John Smith
You have 4 new messages

It is a text file usually of a few bytes in weight, but with enormous power: to allow access to crawlers to scan the site, or to prevent it, totally or partially. This file therefore has the function of establishing which parts of the site can be analysed and potentially indexed by the spiders of Google and other search engines.
Robots.txt file, born way back in 1994 to manage a mailing list, is based on the robots exclusion standard, a protocol created specifically for communication between websites and crawlers. Thanks to this file, it is possible, for example, to block crawler access to a specific directory or page, in order that crawlers will (theoretically) ignore it and not index it.

[divilifeshortcode id=’9530′]
First of all, in order to work, robots file must be placed in the root of the site tree. Once compiled with the instructions you decide to use, crawlers that respect this standard and follow it – not everyone does – will first of all read its content before they start crawling the site.
The principle on which its instructions are based is very simple: it is possible to assign a value to each field. A classic example is the one that determines which user agent can access the site and which areas of the site are inhibited:
User-agent: *
Disallow:
The asterisk stands for all elements, so the instruction above indicates that the site is open to all crawlers. However, in order to see if there are any exceptions relating to parts of the site, we must also read the second instruction.
In the example shown there is no value after disallow, so no area of the site is inhibited.
Using the slash after the disallow instruction would otherwise prevent access to the entire site.
User-agent: *
Disallow: /

The most likely use of this instruction requires that a directory or one or more specific pages be entered in this field, limiting the “no access” to these.
There are several cases where it can be useful to make use of this file:
In this way, for example, it is possible to exclude entire areas of the site as restricted areas or other sections that you do not want to share publicly.
As we have seen, the first function of this file is to regulate access to site data by spiders. Now let’s see what are the main instructions that webmasters can add in the code with a few simple commands.
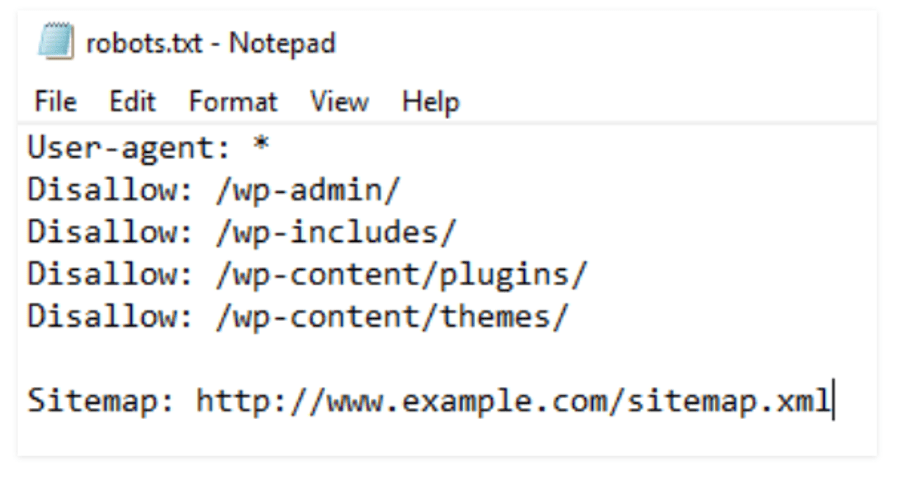
But robots file also has some other important features, such as the ability to tell crawlers where the sitemap is:
Sitemap: https://www.mysite.com/sitemap.xml
In addition to this, which is probably the most popular feature together with those that determine crawler access to the site, robots.txt file also has many other features for more experienced users. Here is a short list:

If there are no specific needs, it is not essential by itself to have robots file. However, given the ease with which it can be created and implemented, it is in any case worth having it, if for no other reason than being able to control which areas of the site are theoretically accessible to search engines and which are not, and also being able to change these settings in every moment.
On the other hand, those who find themselves in one of these situations cannot do without it:
Implementing robots file and configuring it adequately and in detail, therefore, becomes essential for the optimization of large sites, especially for those that make extensive use of parameterized URLs to manage page filters, for example. In fact, these sites easily reach a number of pages that are in the thousands, of which a large number are not particularly significant for search engines.

Since crawlers assign each site a variable but still limited crawl budget (a sort of credit to spend on crawling the pages of the site), it becomes essential to exclude all pages that are not significant for indexing, leaving the budget available for pages that have SEO value.
With a few simple strings it is possible to achieve this result.
Once robots file has been developed by hand or with the use of a software program or a plugin, we must upload it to the site’s hosting server and make sure that it is readable by crawlers, otherwise it was all for nothing.
There are several tools on the web for testing your robots files, but why not rely on Google itself? By using Search console, you can test your robots file and verify that it is correctly configured.
The platform not only shows the instructions contained in the file, but also allows you to test the access of Google bots to the site.
In case you do not want to limit any crawler, it is suggested to set the file as follows:
User-agent: *
Disallow:
The interface returns the test result in a few seconds, indicating whether the Google bots can access it or not. We can then possibly make the appropriate changes, uploading the file and testing it again.
The tool also allows you to test specific Google bots, such as images and news bots.

In this example, the tester tells us that Googlebot – the bot by Google, precisely – cannot access pages with the .html extension.