John Smith
You have 4 new messages

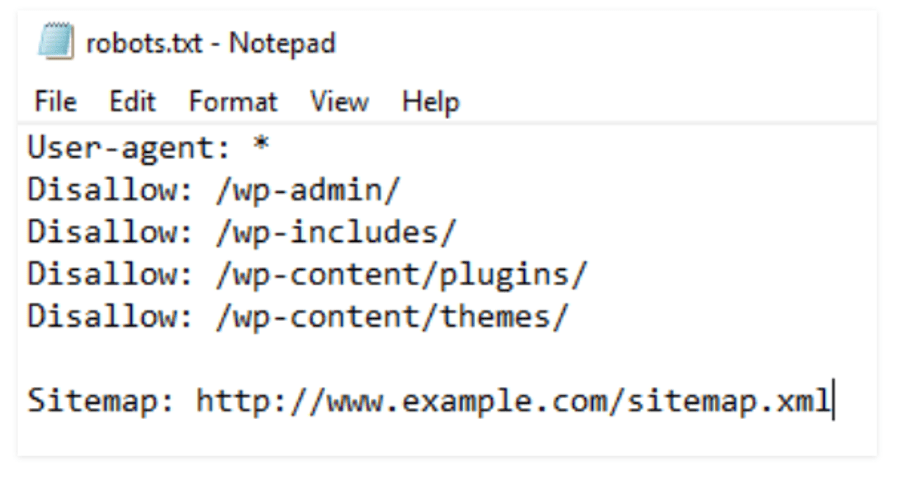
Si tratta di un file di testo del peso solitamente di pochi byte, ma con un enorme potere: consentire l’accesso ai crawler per scansionare il sito, oppure impedirlo, totalmente o in parte. Questo file ha quindi la funzione di stabilire quali parti del sito possono essere analizzate e potenzialmente indicizzate dagli spider di Google e degli altri motori di ricerca.
Il file robots.txt, nato nel lontano 1994 per gestire una mailing list, si basa sul robots exclusion standard, un protocollo nato appositamente per la comunicazione tra i siti web e i crawler. Tramite questo file è possibile ad esempio bloccare l’accesso dei crawler ad una directory o a una pagina specifica, che così (teoricamente) la ignoreranno e non la indicizzeranno.

[divilifeshortcode id=’9530′]
Innanzitutto per poter funzionare il file robots deve essere posizionato nella root dell’alberatura del sito. Una volta compilato con le istruzioni che si decide di utilizzare, i crawler che rispettano questo standard e lo seguono – non tutti lo fanno – come prima cosa, prima di iniziare a scansionare il sito, leggeranno cosa vi è contenuto.
Il principio su cui si basano le sue istruzioni è molto semplice: ad ogni campo può essere attribuito un valore.
Un esempio classico è quello che determina quale user agent può accedere al sito e quali aree del sito sono inibite:
User-agent: *
Disallow:
L’asterisco sta per tutti gli elementi, per cui l’istruzione appena riportata indica che il sito è aperto a tutti i crawler. Per vedere però se ci sono delle eccezioni relative a parti del sito, dobbiamo leggere anche la seconda istruzione.
Nell’esempio riportato non è presente alcun valore dopo disallow, per cui nessuna area del sito è inibita.
L’utilizzo dello slash dopo l’istruzione disallow, impedirebbe al contrario l’accesso all’intero sito.
User-agent: *
Disallow: /

L’utilizzo più probabile di questa istruzione prevede che in questo campo sia inserita una directory o una o più pagine specifiche, limitando a queste il “divieto di accesso”.
Ci sono diversi casi in cui può essere utile fare uso di questo file:
In questo modo si possono escludere ad esempio intere aree del sito come aree riservate o altre sezioni che non si desidera condividere pubblicamente.
Come si è visto la prima funzione di questo file è regolare l’accesso ai dati al sito da parte degli spider. Vediamo quali sono le principali istruzioni che i webmaster possono aggiungere nel codice con pochi semplici comandi.
Ma il file robots possiede anche alcune altre importanti funzionalità, come la possibilità di indicare ai crawler dove si trova la sitemap:
Sitemap: https://www.mysite.com/sitemap.xm
Oltre a questa, che è probabilmente la funzionalità più popolare oltre a quelle che determinano l’accesso dei crawler al sito, il file robots.txt possiede anche molte altre funzionalità per gli utenti più esperti. Riportiamo qui un breve elenco:

Se non ci sono esigenze specifiche, di per sé non è indispensabile avere il file robots. Tuttavia, considerata la facilità con cui può essere creato e implementato, vale in ogni caso la pena averlo anche per il solo fatto di poter controllare quali aree del dito sono teoricamente accessibili ai motori di ricerca e quali no, e di poter cambiare queste impostazioni in ogni momento.
Non può invece farne a meno chi si trova in una di queste situazioni:
Implementare il file robots e configurarlo in maniera adeguata e dettagliata, diventa quindi fondamentale per l’ottimizzazione di siti di grandi dimensioni, soprattutto per quelli che fanno ampio uso di url parametrate per gestire filtri di pagina ad esempio. Questi siti raggiungono infatti facilmente un numero di pagine che è nell’ordine delle migliaia, delle quali un grande numero non particolarmente significative per i motori di ricerca.

Dal momento che i crawler assegnano ad ogni sito un crawl budget (una sorta di credito da spendere per la scansione delle pagine del sito) variabile ma comunque limitato, diventa fondamentale escludere tutte le pagine non significative per l’indicizzazione, lasciando il budget a disposizione per le pagine che invece hanno valore SEO.
Con poche semplici stringhe è possibile ottenere questo risultato.
Una volta messo a punto il file robots a mano o con l’utilizzo di un programma software o di un plugin, dobbiamo caricarlo sul server di hosting del sito e accertarci che questo sia leggibile dai crawler, altrimenti il lavoro è stato inutile.
Ci sono diversi strumenti in rete per testare i propri file robots, ma perché non affidarsi a Google stessa? Tramite Search console è possibile testare il proprio file robots e verificare che sia configurato correttamente.
La piattaforma mostra non solo le istruzioni contenute nel file, ma consente anche di testare l’accesso de bot di Google al sito.
Nel caso in cui non si vogliano mettere limiti ad alcun crawler si suggerisce di impostare il fil come segue:
User-agent: *
Disallow:
L’interfaccia restituisce dopo pochi secondi l’esito del test, indicando se i bot di Google possono accedervi o meno. Possiamo quindi eventualmente fare le opportune modifiche, caricare il file e testarlo di nuovo.
Il tool permette anche di testare bot specifici di Google, quale quello delle immagini e quello delle news.

In questo esempio il tester ci dice che Googlebot, il bot di Google appunto, non può accedere alle pagine con estensione .html.


