John Smith
You have 4 new messages


Il compito principale dei motori di ricerca è quello di offrire contenuti di valore agli utenti. Il valore si può misurare sotto tanti aspetti ma quel che è certo è che per una buona user experience un utente quando effettua una ricerca in rete si aspetta di trovare risultati pertinenti alla sua ricerca e di qualità.
Per offrire un servizio sempre migliore negli anni i motori di ricerca si sono evoluti, elaborando algoritmi sempre più sofisticati per misurare da un lato la qualità intrinseca dei contenuti, dall’altro per correlare fra loro query di ricerca e contenuti per creare una pertinenza sempre maggiore fra search intent (l’intento di ricerca di un utente quando digita qualcosa sulla barra di ricerca) e risultati in SERP (la pagina dei risultati).
Per quanto Google e soci siano attrezzati per gestire miliardi di informazioni, costruendo immense server farm capaci di archiviare una mole impressionante di dati, anche per loro ci sono dei limiti. I motori di ricerca infatti non indicizzano tutte le pagine, ma solo poche di queste. Si stima che solo una minima parte delle pagine teoricamente disponibili sul web siano indicizzate dai motori di ricerca e quindi realmente disponibili:
It’s estimated that Google has only indexed .004% of all Internet pages. (seeker.com)
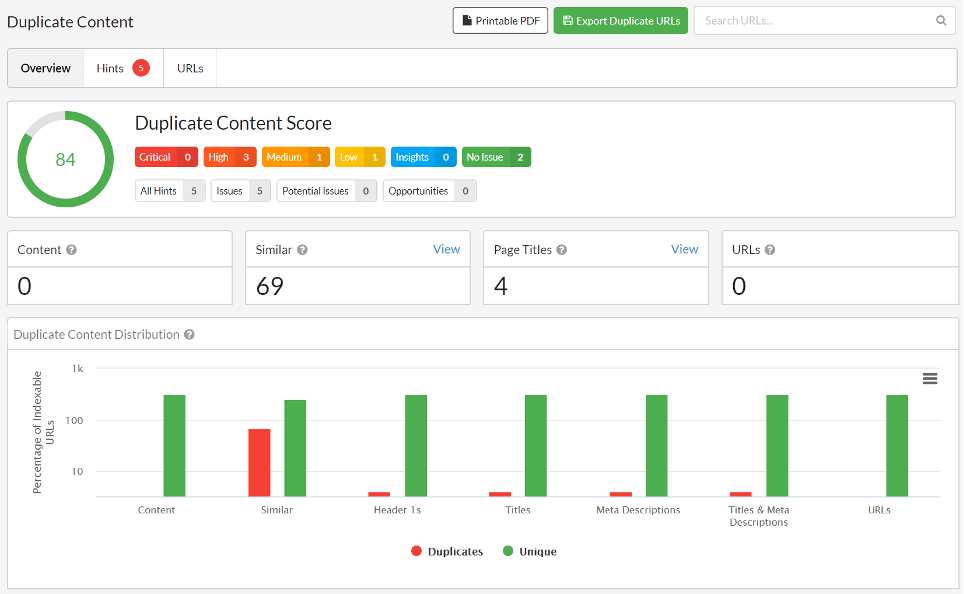
Il web è in effetti pieno di pagine inutili per gli utenti, e tra queste sicuramente ci sono i contenuti duplicati. I duplicati non sono necessariamente pagine identiche fra loro a causa di un plagio: possono essere anche pagine di uno stesso sito create automaticamente dal CMS e che differiscono di poco fra loro.
[divilifeshortcode id=’9530′]
Succede così che i motori di ricerca siano stati programmati per selezionare solo le pagine uniche – non duplicate – e fra queste scegliere quella che ritengono la versione “canonica”, ossia la migliore. Le altre saranno escluse dall’indicizzazione o fortemente penalizzate nel posizionamento.
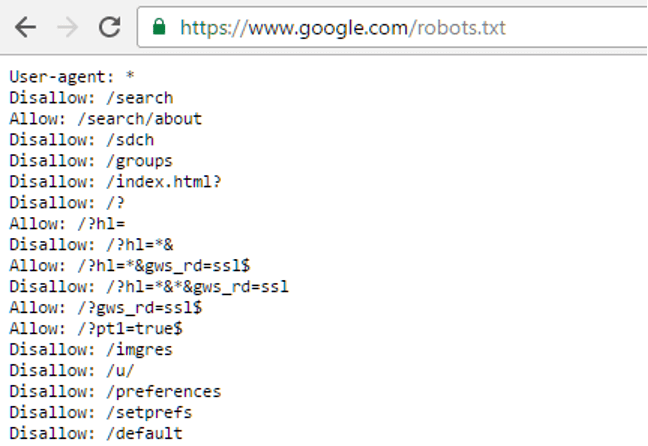
Chi si occupa di SEO sa quindi che dovrà fare molta attenzione a non creare contenuti duplicati nel proprio sito e a gestire la loro possibile esistenza – in alcuni casi inevitabile – attraverso la gestione dell’attributo canonical. Cos’è quindi il canonical? Proviamo a darne una definizione sintetica:
Il canonical è un attributo del tag HTML <link> che può essere applicato a una pagina per indicare qual è la sua versione di riferimento, quella canonica appunto, che i bot di Google e degli altri motori dovrebbero considerare per l’indicizzazione.
<link rel=”canonical” href=”PREFERRED URL” />
Il canonical può essere applicato ovviamente anche alla versione canonica stessa, così come a tutte le versioni duplicate che vi fanno riferimento, indirizzando il potenziale SEO a questa.
Ma a cosa serve e a chi serve realmente questo attributo?
L’attributo canonical serve a indicare al motore di ricerca la pagina canonica fra tante versioni simili o uguali, ma in pratica che effetti ha gestire la canonicalizzazione delle pagine? L’indicazione delle versioni canoniche e di conseguenza dei duplicati da ignorare, ha molti effetti positivi per la SEO:
Come si è visto l’attributo canonical serve a indicare ai motori di ricerca qual è la versione da considerare per l’indicizzazione. Ma nella pratica a chi serve, quali sono i casi in cui è davvero utile?
La possibilità che un sito abbia contenuti duplicati sembrerà a molti un falso problema: in teoria basterebbe non crearne e avere una sola versione di ogni pagina. In realtà alcuni siti vanno incontro a questo problema inevitabilmente. Solitamente quelli con queste caratteristiche:
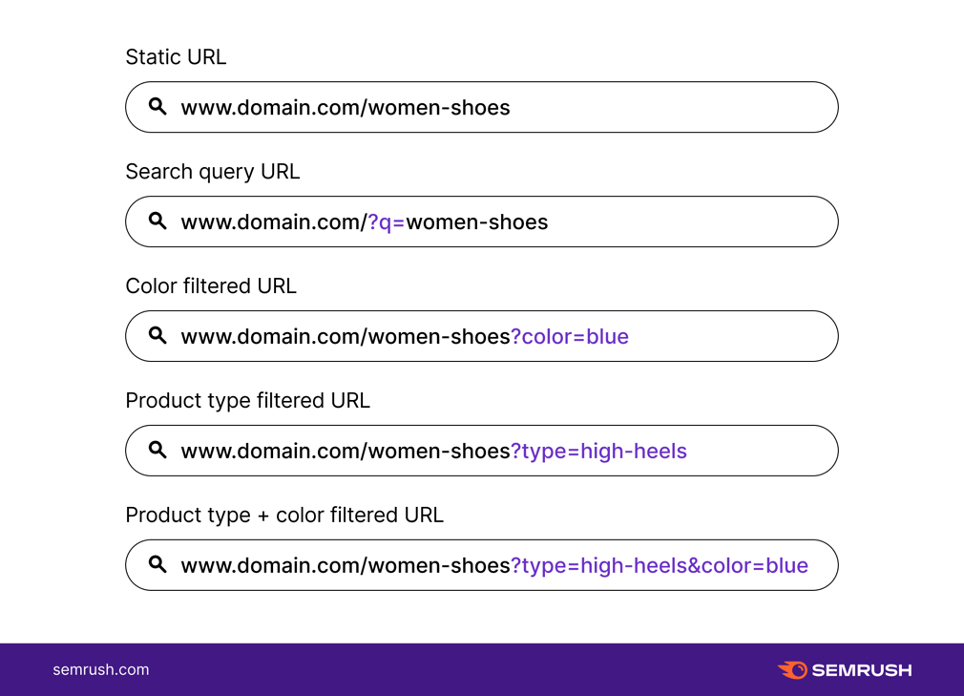
I siti con un’importante storico alle spalle e quindi contenuti stratificati negli anni, incorrono naturalmente nel rischio di avere pagine duplicate, come ad esempio quelle create con la paginazione di un blog; ma il caso in cui i duplicati rappresentano un problema inevitabile per eccellenza è quello dell’e-commerce.
Gli ecommerce sono solitamente gestiti con CMS creati a questo scopo (Magento, Prestashop, ecc.) per poter gestire tutte le esigenze specifiche di un catalogo online. Fra queste c’è la possibilità di creare pagine dinamicamente baste su url parametriche: il classico esempio è la pagina che mostra una selezione di articoli filtrata in base ad un parametro, ad esempio la taglia di un vestito.
Ora che il problema assume contorni molto più concreti, come utilizzare quindi l’attributo canonical al meglio?
Prima di tutto dobbiamo chiarire che questa, come gran parte delle tecniche SEO possono favorire l’indicizzazione e di conseguenza il ranking, ma nella pratica i motori di ricerca possono decidere di non tenerne conto.
Detto questo webmaster e SEO experts non possono lasciare al caso questo importante elemento dell’ottimizzazione. Ci sono vari modi per favorire il riconoscimento di una pagina come canonica:
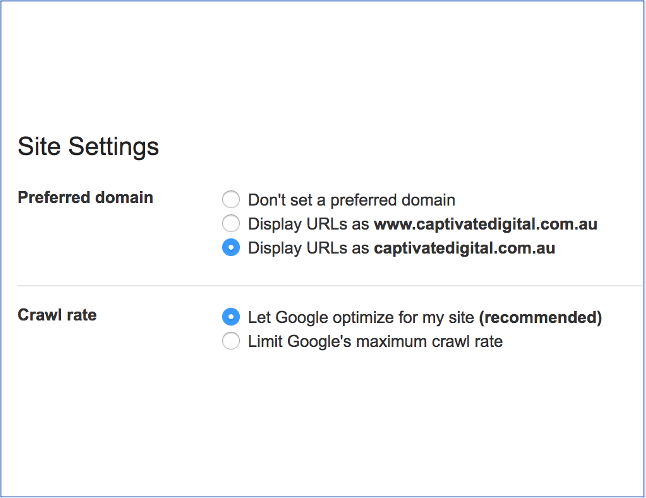
Ci sono diversi metodi per fare una buona canonicalizzazione delle pagine, il requisito fondamentale è conoscere queste tecniche ma prima ancora conoscere la logica con cui vengono create le pagine da parte del nostro CMS, anche e soprattutto quelle con url parametriche.
Esistono diversi tool software e plugin per gestire gli url canonici. Impostati i parametri questi vanno poi a inserire nell’head (l’intestazione della pagina dove sono contenuti i metadati) del codice HTML sorgente gli attributi necessari a canonicalizzare o reindirizzare le risorse.
Il primo step da fare, al di là del metodo e degli strumenti impiegati, è comunque individuare i contenuti simili, decidere la pagina principale o canonica per ogni contenuto al fine di scongiurare la duplicazione dei contenuti.


